
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 포스코 코딩테스트
- ddim
- Generative Models
- dp
- ip-adapter
- colorization
- diffusion models
- classifier-free guidance
- Image Generation
- 코딩테스트
- posco 채용
- KT
- 포스코 채용
- kt인적성
- controlNet
- stable diffusion
- DDPM
- 논문 리뷰
- manganinja
- 과제형 코딩테스트
- 프로그래머스
- Today
- Total
Paul's Grit
[논문 리뷰] [Stable Diffusion] High-Resolution Image Synthesis with Latent Diffusion Models 본문
[논문 리뷰] [Stable Diffusion] High-Resolution Image Synthesis with Latent Diffusion Models
Paul-K 2024. 5. 18. 23:25https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org
1. Introduction
기존의 Diffusion-based models은 pixel-space에서 작동하기 때문에 (pixel 값들을 생성하도록 diffusion model이 학습되게 때문에) 학습과 추론 시, 코스트가 클 뿐만 아니라 고화질의 이미지에서 생성 성능의 한계가 있다.
본 논문에서는 autoencoder에 의해서 학습되는 latent space에서 diffusion model을 학습시키는 Latent Diffusion Models (LDMs)을 소개한다.
LDM에서는 DM이 작은 차원의 latent space에서 작동함으로써 고화질 이미지 생성으로 DM을 확장(scale)할 수 있다. 또한 super-resolution, inpainting and semantic synthesis과 같은 conditioning task에서도 LDM을 적용하여 높은 성능을 달성한다. 추가적으로, cross-attention 방법을 사용하여 class-conditional, text-to-image, layout-to-image models과 같은 multi-modal 학습을 가능하게 한다.
3. Methods
3.1 Perceptual Image Compression
기존 DMs은 pixel-space에서 동작하기 때문에 high-resolution 이미지에서는 계산 시간과 리소스 측면에서 코스트가 크다.

이와 달리, 본 논문에서는 diffusion process를 진행하기에 앞서 Autoencoder를 사용하여 이미지를 latent vector인 $z$로 압축한다. 실제 이미지 $x$가 주어졌을 때, 인코더 $\mathcal{E}$를 거쳐서 latent vector $z=\mathcal{E}(x)$로 압축(encode) 한다. 디코더 $\mathcal{D}$는 latext vector $z$가 주어졌을 때, 합성 이미지 $\tilde{x}=\mathcal{D}(z)=\mathcal{D}(\mathcal{E}(x))$를 생성한다.
인코더는 이미지를 낮을 차원으로 downsample하게 되는데, 본 논문에서는 차원을 줄이는 비율을 {1, 2, 4, 8, 16, 32} 이렇게 2의 승수로 정하였다. 비율이 1일 때는 기존의 DMs과 동일하다. 실험 파트에서 설명이 나오지만 비율을 4, 8, 16으로 가져가는 것이 대체적으로 높은 성능을 달성하였다.
Latent space에서의 높은 분산을 피하기 위해서, latent space에 regularization을 가하였다. 두 가지 방법을 사용하였다. 첫번째로는 VAE에서처럼 standard normal 분포와 KL 패널티를 추가하는 KL-reg.가 있다. 두번째로는 디코더에 vector quantization layer를 사용하는 VQ-reg.라는 방법이 있었다.
3.2 Latent Diffusion Models
기존의 diffusion models은 아래와 같은 목적 함수 $L_{DM}$를 사용한다. 이와 달리 LDM은 low dimensional space에 있는 latent vector $z_t$를 사용한다. LDM의 목적 함수 $L_{LDM}$에서 $x_t$가 $z_t$로 대체된 것을 확인할 수 있다.


With our trained perceptual compression models consisting of $\mathcal{E}$ and $\mathcal{D}$, we now have access to an efficient, low-dimensional latent space in which high-frequency, imperceptible details are abstracted away.
Compared to the high-dimensional pixel space, this space is more suitable for likelihood-based generative models, as they can now (i) focus on the important, semantic bits of the data and (ii) train in a lower dimensional, computationally much more efficient space.
신경망은 기존의 DMs와 동일하게 U-Net을 사용하였다.
3.3 Conditioning Mechanisms
Diffusion model에서도 생성 조건을 주는 것이 가능하다, $p(z|y)$. LDM에서도 동일하게 가능한데, $\epsilon(z_t, t, y)$와 같이 input에 condition $y$가 추가된다. 이때, $y$는 text, semantic maps, 또는 image-to-image translation 등 다양한 형태 또는 modality를 가질 수 있다.
LDM에서는 cross-attention을 사용하여 conditioning 기능을 추가했다.
We turn DMs into more flexible conditional image generators by augmenting their underlying UNet backbone with the cross-attention mechanism, which is effective for learning attention-based models of various input modalities.
LDM에서는 다양한 modality를 가질 수 있는 $y$를 처리하기 위해 학습 가능한 domain-specific encoder $\tau_\theta$를 추가하고, $y$를 intermediate representation $\tau_\theta(y)$으로 projection 한다.
Intermediate representation $\tau_\theta(y)$는 다시 cross-attention layer에 의해서 UNet의 각 레이어에 mapping 된다. cross-attention layer는 트랜스포머와 동일하게 아래와 같이 Q, K, V로 구현된다.
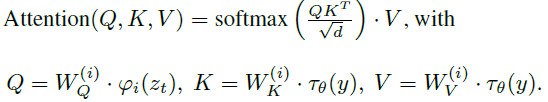
Here, $\varphi_i(z_t)$ denotes a (flatten) intermediate representation of the UNet implementing $\epsilon_\theta$ and $W_V^{(i)}$, $ W_Q^{(i)} $ & $ W_K^{(i)} $ are learnable projection matrices.
Conditional LDM은 아래와 같은 목적 함수를 가진다.

4. Experiments
4.1 On Perceptual Compression Tradeoffs
Downsampling factors $f \in \{1, 2, 4, 8, 16, 32\}$에 따른 결과 값들의 차이를 확인한다. (where LDM-1 corresponds to pixel-based DMs). 대체적으로 4, 8, 16의 compression을 사용할 때 높은 효율성과 성능을 보인다.

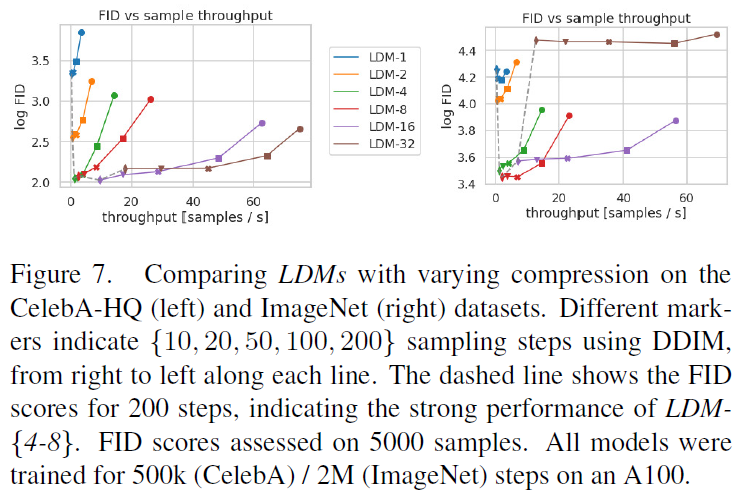
We see that, i) small downsampling factors for LDM-{1, 2} result in slow training progress, whereas ii) overly large values of f cause stagnating fidelity after comparably few training steps. Revisiting the analysis above (Fig. 1 and 2) we attribute this to i) leaving most of perceptual compression to the diffusion model and ii) too strong first stage compression resulting in information loss and thus limiting the achievable quality. LDM-{4-6} strike a good balance between efficiency and perceptually faithful results, which manifests in a significant FID gap of 38 between pixel-based diffusion (LDM-1) and LDM-8 after 2M training steps.
4.2. Image Generation with Latent Diffusion
256 x 256 이미지의 unconditional 생성 성능을 확인한다.

4.3. Conditional Latent Diffusion
4.3.1 Transformer Encoders for LDMs
Conditioning problem에 대한 실험을 다룬다. text-to-image modeling에서는 아래와 같은 모델 구조를 사용한다.
we train a 1.45B parameter KL-regularized LDM conditioned on language prompts on LAION-400M. We employ the BERT-tokenizer and implement $\tau_\theta$ as a transformer to infer a latent code which is mapped into the UNet via (multi-head) cross-attention.


아래는 layout-to-image synthesis 태스크 결과이다.

아래는 ImageNet class-conditional 생성 성능이다.

4.3.2 Convolutional Sampling Beyond $256^2$
semantic synthesis 태스크에서 256 해상도로 학습된 LDM이 더 큰 해상도 512 x 1024에서 generalize될 수 있다.

4.4. Super-Resolution with Latent Diffusion
Super-resolution 태스크에서 SR3와 비교한 결과이다.


4.5. Inpainting with Latent Diffusion
Image inpainting 태스크 실험 결과이다.


5. Limitations
While LDMs significantly reduce computational requirements compared to pixel-based approaches, their sequential sampling process is still slower than that of GANs. Moreover, the use of LDMs can be questionable when high precision is required: although the loss of image quality is very small in our $f = 4$ autoencoding models, their reconstruction capability can become a bottleneck for tasks that require fine-grained accuracy in pixel space. We assume that our superresolution models (Sec. 4.4) are already somewhat limited in this respect.
6. Concludion
We have presented latent diffusion models, a simple and efficient way to significantly improve both the training and sampling efficiency of denoising diffusion models without degrading their quality. Based on this and our cross-attention conditioning mechanism, our experiments could demonstrate favorable results compared to state-of-the-art methods across a wide range of conditional image synthesis tasks without task-specific architectures.
'논문 리뷰 > Generative models' 카테고리의 다른 글
| [논문 리뷰] [ControlNet] Adding Conditional Control to Text-to-Image Diffusion Models (0) | 2025.01.10 |
|---|---|
| [DALL-E] Zero-Shot Text-to-Image Generation (0) | 2024.05.27 |
| [논문 리뷰] [CLIP] Learning Transferable Visual Models From Natural Language Supervision (1) | 2024.05.24 |
| A Dive into Vision-Language Models (0) | 2024.05.24 |
| [논문 리뷰] [DDPM] Denoising Diffusion Probabilistic Models (0) | 2024.05.14 |



