
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- dp
- manganinja
- 논문 리뷰
- ddim
- 포스코 채용
- 코딩테스트
- KT
- Image Generation
- diffusion models
- kt인적성
- ip-adapter
- DDPM
- Generative Models
- 프로그래머스
- 포스코 코딩테스트
- 과제형 코딩테스트
- stable diffusion
- classifier-free guidance
- controlNet
- colorization
- posco 채용
- Today
- Total
Paul's Grit
[논문 리뷰] [ControlNet] Adding Conditional Control to Text-to-Image Diffusion Models 본문
[논문 리뷰] [ControlNet] Adding Conditional Control to Text-to-Image Diffusion Models
Paul-K 2025. 1. 10. 18:32https://arxiv.org/abs/2302.05543
Adding Conditional Control to Text-to-Image Diffusion Models
We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks the production-ready large diffusion models, and reuses their deep and robust encoding layers pr
arxiv.org
Abstract
대규모 사전학습된 텍스트-이미지 diffusion 모델에 공간적 조건 제어 (spatial conditioning controls)를 추가할 수 있는 아키텍처인 ControlNet을 제안한다.
ControlNet은 대규모 diffusion 모델의 학습된 가중치를 고정하고, 수십억 개의 이미지로 사전학습된 강력하고 깊은 인코딩 레이어를 백본으로 재활용하여 다양한 조건 제어를 학습한다. 신경망 아키텍처는 "제로 컨볼루션(zero convolutions)"(제로로 초기화된 컨볼루션 레이어)으로 연결되어, 파라미터가 점진적으로 0에서 성장하도록 하고, 미세조정(finetuning)에 유해한 노이즈가 영향을 미치지 않도록 보장한다.
Stable Diffusion을 사용하여 단일 또는 다중 조건, 프롬프트의 유무와 같은 다양한 조건 제어(e.g., edges, depth, segmentation, human pose, etc.)를 테스트하였다. ControlNet 학습이 소규모(<50k)와 대규모(>1m) 데이터셋에서도 안정적으로 수행됨을 보였다.
1. Introduction

우리 중 많은 사람들은 독창적인 이미지를 통해 시각적 영감을 포착하고 싶어하는 순간을 경험한 적이 있다. 텍스트-이미지 diffusion 모델의 등장으로, 이제 텍스트 프롬프트를 입력하는 것만으로도 시각적으로 놀라운 이미지를 생성할 수 있게 되었다. 그러나 텍스트-이미지 모델은 이미지의 공간적 구성을 제어하는 데 한계가 있다. 복잡한 레이아웃, 자세, 형태와 모양을 정확히 표현하는 것은 텍스트 프롬프트만으로는 어려울 수 있다. 우리의 정신적 이미지를 정확히 반영하는 이미지를 생성하려면 프롬프트를 편집하고, 결과 이미지를 확인한 후 다시 편집하는 반복적인 시행착오가 종종 필요하다.
사용자가 원하는 이미지 구성을 직접 지정할 수 있도록 추가 이미지를 제공함으로써 더 세밀한 공간적 제어를 가능하게 할 수 있을까? 컴퓨터 비전 및 머신러닝 분야에서는 이러한 추가 이미지(예: 엣지 맵, 인간 자세 스켈레톤, 세그멘테이션 맵, 깊이, 법선 등)를 이미지 생성 과정에서 조건으로 사용하는 경우가 많다. 이미지-이미지 변환 모델은 조건 이미지를 대상 이미지로 매핑하는 과정을 학습한다. 연구 커뮤니티는 또한 spatial masks, editing instructions, fine-tuning을 통한 개인화 등을 통해 텍스트-이미지 모델을 제어하려는 시도를 해왔다. 몇 가지 문제(예: 이미지 변형 생성, 인페인팅)는 노이즈 감소 diffusion 과정 제약이나 주의(attention) 레이어 활성화 편집과 같은 학습이 필요 없는 기법으로 해결할 수 있다. 그러나 깊이-이미지 변환, 자세-이미지 변환 등과 같은 더 다양한 문제는 end-to-end learning과 데이터 기반 솔루션을 요구한다.
대규모 텍스트-이미지 diffusion 모델에서 조건부 제어를 end-to-end 방식으로 학습하는 것은 도전적인 과제이다. 특정 조건에 대한 학습 데이터의 양은 일반적인 텍스트-이미지 학습에 사용 가능한 데이터에 비해 크게 적을 수 있다. 예를 들어, 다양한 특정 문제(예: 객체의 형태/법선, 인간 자세 추출 등)에 대한 최대 데이터셋은 보통 약 10만 개 정도이며, 이는 Stable Diffusion 학습에 사용된 LAION-5B 데이터셋보다 50,000배나 작다. 대규모 사전학습된 모델을 제한된 데이터로 직접 미세조정(fine-tuning)하거나 추가 학습을 진행하면 과적합(overfitting) 및 치명적인 망각(catastrophic forgetting)이 발생할 수 있다. 연구자들은 학습 가능한 파라미터의 수나 계급(rank)을 제한함으로써 이러한 망각을 완화할 수 있음을 보여주었다. 본 문제에서는 복잡한 형태와 다양한 고차원적 의미론을 가진 자연 상태(in-the-wild)의 조건부 이미지를 처리하기 위해 더 깊거나 맞춤화된 신경망 아키텍처를 설계하는 것이 필요할 수 있다.
본 논문은 대규모 사전학습된 텍스트-이미지 diffusion 모델(본 구현에서는 Stable Diffusion)을 위한 조건부 제어를 학습하는 end-to-end 신경망 아키텍처인 ControlNet을 제안한다. ControlNet은 대규모 모델의 품질과 기능을 유지하기 위해 모델의 파라미터를 고정하고, 인코딩 레이어의 학습 가능한 복사본을 생성한다. 이 아키텍처는 대규모 사전학습된 모델을 다양한 조건부 제어를 학습하기 위한 강력한 백본(backbone)으로 활용한다. 학습 가능한 복사본과 고정된 원본 모델은 제로 컨볼루션 레이어 (zero convolution layers)로 연결되며, 이 레이어의 가중치는 초기값으로 0으로 설정되어 학습 과정에서 점진적으로 성장한다. 이러한 아키텍처는 학습 초기에 대규모 diffusion 모델의 깊은 특징(deep features)에 유해한 노이즈가 추가되지 않도록 보장하며, 학습 가능한 복사본에서 대규모 사전학습 백본이 이러한 노이즈로 인해 손상되지 않도록 보호한다.
우리의 실험 결과, ControlNet은 캐니 엣지 (Canny Edge), 허프 선(Hough lines), 사용자의 낙서, 인간 키포인트 (key points), 세그멘테이션 맵 (sementation maps), 형태 법선(shape normals), 깊이(depth) 등 다양한 조건 입력을 활용하여 Stable Diffusion을 제어할 수 있음을 확인하였다(Figure 1). 우리는 단일 조건 이미지를 사용하여, 텍스트 프롬프트의 유무에 관계없이 접근 방식을 테스트하였으며, 다중 조건의 조합을 지원하는 방법도 시연하였다. 추가적으로, ControlNet의 학습이 다양한 크기의 데이터셋에서 견고하고 확장 가능하며, 깊이-이미지 변환과 같은 일부 작업에서는 단일 NVIDIA RTX 3090Ti GPU로 학습한 ControlNet이 대규모 컴퓨팅 클러스터에서 학습된 산업용 모델과 경쟁력 있는 결과를 달성할 수 있음을 보고하였다. 마지막으로, 모델의 각 구성 요소가 기여하는 바를 조사하기 위한ablative study를 수행하였고, 사용자 연구를 통해 여러 강력한 조건부 이미지 생성 기반 모델과 우리의 모델을 비교하였다.
요약
- 사전학습된 텍스트-이미지 diffusion 모델에 효율적인 미세조정을 통해 spatially localized input conditions을 추가할 수 있는 신경망 아키텍처인 ControlNet을 제안
- 캐니 엣지, 허프 선(Hough lines), 사용자 낙서, 인간 키포인트, 세그멘테이션 맵, 형태 법선(shape normals), 깊이(depth), 만화 선화를 조건으로 Stable Diffusion을 제어할 수 있는 사전학습된 ControlNet을 제안
- 여러 대안 아키텍처와 비교한 ablative experiments 및 다양한 작업에서 baseline을 중심으로 한 사용자 연구를 통해 본 방법을 검증
2. Related works
2.1 Finetuning Neural Networks
신경망을 미세조정하는 한 가지 방법은 추가적인 학습 데이터를 사용하여 직접 학습을 계속 진행하는 것이다. 그러나 이러한 접근 방식은 과적합(overfitting), 모드 붕괴(mode collapse), 치명적인 망각(catastrophic forgetting)을 초래할 수 있다. 이러한 문제를 방지하기 위한 미세조정 전략을 개발하는 데 많은 연구가 집중되어 왔다.
HyperNetwork는 자연어 처리(NLP) 커뮤니티에서 기원한 접근법으로 , recurrent neural network을 학습하여 더 큰 신경망의 가중치에 영향을 주는 것을 목표로 한다. 이 접근법은 생성적 적대 신경망(GAN)을 활용한 이미지 생성에도 적용된 바 있다. Heathen et al.과 Kurumuz는 Stable Diffusion에서 HyperNetwork를 구현하여 출력 이미지의 예술적 스타일을 변경하는 데 사용하였다.
Adapter 방법은 사전학습된 Transformer 모델에 새로운 모듈 레이어를 삽입하여 다른 태스크에 맞게 커스터마이징하기 위해 NLP에서 널리 사용되고 있다. 컴퓨터 비전에서는 이 방법이 점진적 학습(incremental learning)과 도메인 적응(domain adaptation)에 활용된다. 이 기술은 종종 CLIP과 함께 사용되어 사전학습된 백본(backbone) 모델을 다양한 태스크로 전이하는 데 적용된다. 최근에는 Vision Transformer와 ViT-Adapter에서도 성공적인 결과를 보여주었다. 본 연구와 동시 진행된 연구인 T2I-Adapter는 Stable Diffusion을 외부 조건에 맞게 적응시킨다.
Additive Learning은 원래 모델의 가중치를 고정(freezing)하고, 학습된 가중치 마스크, 가지치기(pruning), 또는 하드 어텐션(hard attention)을 활용하여 소수의 새로운 파라미터를 추가함으로써 망각(forgetting)을 방지한다. Side-Tuning은 추가된 네트워크와 고정된 모델의 출력을 선형적으로 혼합(linear blending)하여 추가 기능을 학습하는 사이드 브랜치(side branch) 모델을 사용하며, 이 혼합은 사전에 정의된 가중치 스케줄에 따라 진행된다.
Low-Rank Adaptation (LoRA)는 많은 과적합된 모델이 저차원의 내재적 공간에 존재한다는 관찰을 기반으로, 저차원 행렬을 사용하여 파라미터의 오프셋을 학습함으로써 치명적인 망각(catastrophic forgetting)을 방지한다.
Zero-Initialized Layers는 ControlNet에서 네트워크 블록을 연결하는 데 사용된다. 신경망에서 가중치 초기화와 조작에 관한 연구는 광범위하게 논의되어 왔다. 예를 들어, 가우시안 초기화는 제로 초기화보다 위험이 적을 수 있음이 보고된 바 있다. 최근 Nichol et al.은 diffusion 모델의 컨볼루션 레이어 초기 가중치를 조정하여 학습을 개선하는 방법을 논의하였으며, 그들이 구현한 "제로 모듈(zero module)"은 가중치를 0으로 조정하는 극단적인 사례이다. Stability의 모델 카드에서도 신경망 레이어에서 제로 가중치 사용에 대해 언급하였다. 초기 컨볼루션 가중치 조작은 ProGAN, StyleGAN, Noise2Noise에서도 논의된 바 있다.
2.2. Image Diffusion
Image Diffusion Models는 Sohl-Dickstein et al.에 의해 처음 소개되었으며, 최근 이미지 생성에 적용되고 있다. Latent Diffusion Models(LDM)는 잠재 이미지 공간(latent image space)에서 diffusion 단계를 수행하여 계산 비용을 줄인다. 텍스트-이미지 diffusion 모델은 CLIP과 같은 사전학습된 언어 모델을 통해 텍스트 입력을 잠재 벡터로 인코딩하여 최첨단 이미지 생성 성능을 달성한다. Glide는 이미지 생성 및 편집을 지원하는 텍스트 기반 diffusion 모델이다. Disco Diffusion는 텍스트 프롬프트를 CLIP 가이던스와 함께 처리한다. Stable Diffusion은 Latent Diffusion의 대규모 구현이다. Imagen은 잠재 이미지를 사용하지 않고 피라미드 구조를 활용하여 직접 픽셀을 확산시킨다. 상업용 제품으로는 DALL-E2와 Midjourney가 있다.
Controlling Image Diffusion Models는 개인화, 커스터마이징, 또는 특정 작업에 맞춘 이미지 생성을 가능하게 한다. 이미지 diffusion 과정은 색상 변동 및 인페인팅에 직접적인 제어를 제공한다. 텍스트 기반 제어 방법은 프롬프트 조정, CLIP 특징 조작, 크로스-어텐션 수정에 초점을 맞춘다. MakeAScene은 세그멘테이션 마스크를 토큰으로 인코딩하여 이미지 생성을 제어하며, SpaText는 세그멘테이션 마스크를 지역화된 토큰 임베딩으로 매핑한다. GLIGEN은 diffusion 모델의 어텐션 레이어에서 새로운 파라미터를 학습하여 기반이 있는 생성(grounded generation)을 수행한다. Textual Inversion과 DreamBooth는 사용자가 제공한 소량의 예제 이미지를 활용하여 이미지 diffusion 모델을 미세조정함으로써 생성된 이미지의 콘텐츠를 개인화할 수 있다. 프롬프트 기반 이미지 편집은 프롬프트를 통해 이미지를 조작할 수 있는 실용적인 도구를 제공한다. Voynov et al.은 스케치를 활용하여 diffusion 과정을 맞추는 최적화 방법을 제안하였다.
2.3 Image-to-Image Translation
Conditional GANs와 Transformer는 서로 다른 이미지 도메인 간의 매핑을 학습할 수 있다. 예를 들어, Taming Transformer는 비전 트랜스포머(Vision Transformer) 기반 접근법이며, Palette는 처음부터 학습된 조건부 diffusion 모델이다. PITI는 사전학습 기반 조건부 diffusion 모델로, 이미지-이미지 변환을 위해 설계되었다. 사전학습된 GAN을 조작하면 특정 이미지-이미지 변환 작업을 수행할 수 있으며, 예를 들어 StyleGAN은 추가 인코더를 통해 제어할 수 있다.
3. Method

3.1 ControlNet
ControlNet은 신경망의 블록에 추가적인 조건을 삽입한다(Figure 2). 여기서 "네트워크 블록"이라는 용어는 일반적으로 신경망의 단일 단위를 구성하기 위해 함께 사용되는 신경 레이어 집합을 의미한다. 예를 들어, ResNet block, Conv-BN-ReLU block, multi-head attention block, Transformer block 등이 이에 해당한다. 신경망 블록이 $F(\cdot; \Theta)$로 표현되고, 파라미터 $\Theta$를 가진 상태에서 입력 특징 맵 $x$를 또 다른 특징 맵 $y$로 변환하다고 가정하면, 이는 다음과 같이 표현된다.
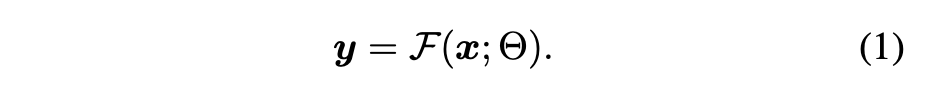
본 설정에서 $x$와 $y$는 일반적으로 2D 특징 맵이다. 즉, \( x \in \mathbb{R}^{h \times w \times c} \)이며, 여기서 \(\{h, w, c\}\)는 각각 특징 맵의 높이(\(h\)), 너비(\(w\)), 채널 수(\(c\))를 나타낸다 (Figure 2a).
ControlNet을 이러한 사전학습된 신경망 블록에 추가하기 위해, 원래 블록의 파라미터 \(\Theta\)를 고정(동결)하고, 동시에 해당 블록을 파라미터 \(\Theta_c\)를 가진 학습 가능한 복사본으로 복제한다(Figure 2b). 학습 가능한 복사본은 외부 조건 벡터 \(c\)를 입력으로 받는다. 이 구조를 Stable Diffusion과 같은 대규모 모델에 적용할 경우, 고정된 파라미터 \(\Theta\)는 수십억 개의 이미지로 학습된 프로덕션 수준의 모델을 유지하며, 학습 가능한 복사본 \(\Theta_c\)는 이러한 대규모 사전학습 모델을 재사용하여 다양한 입력 조건을 처리할 수 있는 깊고, 강력하며, 견고한 백본을 구축한다.
학습 가능한 복사본은 고정된 모델과 제로 컨볼루션 레이어로 연결되며, 이는 \( Z(\cdot; \cdot) \)로 표현된다. 구체적으로, \( Z(\cdot; \cdot) \)는 가중치와 바이어스가 모두 0으로 초기화된 \( 1 \times 1 \) 컨볼루션 레이어이다. ControlNet을 구축하기 위해, 각각 파라미터 \(\Theta_{z1}\)과 \(\Theta_{z2}\)를 가진 두 개의 제로 컨볼루션 인스턴스를 사용한다. 완전한 ControlNet은 다음과 같이 계산된다:

여기서 \( y_c \)는 ControlNet 블록의 출력이다. 학습 초기 단계에서, 제로 컨볼루션 레이어의 가중치와 바이어스 파라미터가 모두 0으로 초기화되었기 때문에, 식 (2)의 두 \( Z(\cdot; \cdot) \) 항이 모두 0으로 평가된다. 즉,
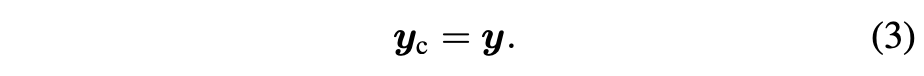
이와 같은 방식으로, 학습이 시작될 때 학습 가능한 복사본의 신경망 레이어의 hidden states에 유해한 노이즈가 영향을 미칠 수 없게 된다. 또한 \( Z(c; \Theta_{z1}) = 0 \)이고, 학습 가능한 복사본이 입력 이미지 \( x \)도 수신하므로, 학습 가능한 복사본은 완전한 기능을 갖추고 있으며, 대규모 사전학습 모델의 능력을 유지하여 추가 학습을 위한 강력한 백본 역할을 할 수 있다. 제로 컨볼루션은 초기 학습 단계에서 그래디언트에 의한 랜덤 노이즈를 제거함으로써 이 백본을 보호한다. 제로 컨볼루션의 그래디언트 계산에 대한 자세한 내용은 보충 자료에 서술하였다.
3.2. ControlNet for Text-to-Image Diffusion

Stable Diffusion을 예로 들어, ControlNet이 대규모 사전학습된 diffusion 모델에 조건부 제어를 추가하는 방법을 설명한다. Stable Diffusion은 본질적으로 인코더, 중간 블록, 그리고 스킵 연결된 디코더로 구성된 U-Net 구조이다. 인코더와 디코더는 각각 12개의 블록을 포함하며, 중간 블록을 포함하여 전체 모델은 25개의 블록으로 이루어져 있다.
이 25개 블록 중, 8개는 다운샘플링 또는 업샘플링 컨볼루션 레이어이고, 나머지 17개는 주요 블록으로, 각 블록은 4개의 ResNet 레이어와 2개의 Vision Transformer (ViT)를 포함한다. 각 ViT는 여러 크로스 어텐션(cross-attention) 및 셀프 어텐션(self-attention) 메커니즘을 포함한다. 예를 들어, Figure 3a에서 "SD Encoder Block A"는 4개의 ResNet 레이어와 2개의 ViT로 구성되어 있으며, "×3"은 이 블록이 세 번 반복됨을 나타낸다. 텍스트 프롬프트는 CLIP 텍스트 인코더 [66]를 사용해 인코딩되며, diffusion 타임스텝은 위치 인코딩(positional encoding)을 사용하는 타임 인코더를 통해 인코딩된다.
ControlNet 구조는 U-Net의 각 인코더 레벨에 적용된다(Figure 3b). 특히, ControlNet은 Stable Diffusion의 12개의 인코딩 블록과 1개의 중간 블록에 대해 학습 가능한 복사본을 생성하는 데 사용된다. 12개의 인코딩 블록은 4개의 해상도(64 × 64, 32 × 32, 16 × 16, 8 × 8)에서 각각 3번씩 반복된다. 각 블록의 출력은 U-Net의 12개의 스킵 연결과 1개의 중간 블록에 추가된다. Stable Diffusion이 전형적인 U-Net 구조를 따르기 때문에, 이 ControlNet 아키텍처는 다른 모델에도 적용 가능할 가능성이 높다.
ControlNet을 연결하는 방식은 계산 효율적이다. 고정된 복사본의 파라미터가 동결되어 있으므로, 원래 고정된 인코더에서는 미세조정을 위한 그래디언트 계산이 필요하지 않다. 이러한 접근 방식은 학습 속도를 높이고 GPU 메모리를 절약한다. NVIDIA A100 PCIE 40GB에서 테스트한 결과, ControlNet을 사용한 Stable Diffusion 최적화는 ControlNet 없이 Stable Diffusion을 최적화하는 경우에 비해 각 학습 반복에서 약 23% 더 많은 GPU 메모리와 34% 더 많은 시간이 소요된다.
이미지 diffusion 모델은 이미지를 점진적으로 디노이즈하여 학습 도메인에서 샘플을 생성하도록 학습된다. 디노이즈 과정은 픽셀 공간(pixel space) 또는 학습 데이터로부터 인코딩된 잠재 공간(latent space)에서 발생할 수 있다. Stable Diffusion은 학습 과정이 안정화되는 것으로 알려진 잠재 이미지를 학습 도메인으로 사용한다 [72]. 구체적으로, Stable Diffusion은 VQ-GAN [19]과 유사한 전처리 방법을 사용하여 \(512 \times 512\) 픽셀 공간 이미지를 더 작은 \(64 \times 64\) 잠재 이미지로 변환한다. Stable Diffusion에 ControlNet을 추가하기 위해, 각 입력 조건 이미지(예: 엣지, 자세, 깊이 등)를 \(512 \times 512\) 크기에서 Stable Diffusion의 크기에 맞는 \(64 \times 64\) 특징 공간 벡터로 변환한다. 이를 위해, 네 개의 컨볼루션 레이어로 구성된 작은 네트워크 \(E(\cdot)\)를 사용한다. 이 네트워크는 \(4 \times 4\) 커널과 \(2 \times 2\) 스트라이드를 가지며, ReLU 활성화 함수와 함께 각각 16, 32, 64, 128 채널을 사용한다. 이 네트워크는 가우시안 가중치로 초기화되며, 전체 모델과 함께 공동 학습된다. 이를 통해 이미지 공간의 조건 \(c_i\)를 특징 공간의 조건 벡터 \(c_f\)로 다음과 같이 인코딩한다:

3.3 Training
주어진 입력 이미지 \( z_0 \)에서, 이미지 diffusion 알고리즘은 점진적으로 노이즈를 추가하여 노이즈가 포함된 이미지 \( z_t \)를 생성한다. 여기서 \( t \)는 노이즈가 추가된 횟수를 나타낸다. 시간 단계 \( t \), 텍스트 프롬프트 \( c_t \), 그리고 작업에 특화된 조건 \( c_f \)를 포함한 조건 집합이 주어졌을 때, 이미지 diffusion 알고리즘은 네트워크 \( \epsilon_\theta \)를 학습하여 노이즈가 추가된 이미지 \( z_t \)에 포함된 노이즈를 다음과 같이 예측한다:

여기서 \( L \)은 전체 diffusion 모델의 학습 목표(objective)를 나타낸다. 이 학습 목표는 ControlNet을 사용하여 diffusion 모델을 미세조정(finetuning)하는 데 직접적으로 사용된다.
학습 과정에서, 텍스트 프롬프트 \( c_t \)의 50%를 무작위로 빈 문자열로 대체한다. 이 접근법은 ControlNet이 입력 조건 이미지(예: 엣지, 자세, 깊이 등)의 의미를 직접적으로 인식하는 능력을 향상시키며, 프롬프트를 대체하는 역할을 한다.
학습 과정 중, 제로 컨볼루션은 네트워크에 노이즈를 추가하지 않기 때문에 모델은 항상 고품질 이미지를 예측할 수 있어야 한다. 우리는 모델이 제어 조건을 점진적으로 학습하지 않고, 입력 조건 이미지를 갑작스럽게 성공적으로 따르게 된다는 것을 관찰하였다. 이는 보통 10,000번 미만의 최적화 단계에서 발생한다. Figure 4에 나타난 것처럼, 이를 "갑작스러운 수렴 현상(sudden convergence phenomenon)"이라고 부른다.
4. Experiments

4.1 Qualitative Results
Figure 1은 여러 프롬프트 설정에서 생성된 이미지를 보여준다. Figure 7은 프롬프트 없이 다양한 조건에서의 결과를 나타내며, 이 경우 ControlNet은 다양한 입력 조건 이미지에서 콘텐츠의 의미를 견고하게 해석하는 능력을 보여준다.
4.2. Ablative Study

우리는 ControlNet의 대체 구조를 다음과 같은 방식으로 연구하였다: (1) 제로 컨볼루션을 가우시안 가중치로 초기화된 표준 컨볼루션 레이어로 대체하고, (2) 각 블록의 학습 가능한 복사본을 단일 컨볼루션 레이어로 대체한 간소화된 구조를 제안하며 이를 ControlNet-lite라고 명명하였다. 이러한 ablative structures의 자세한 내용은 보충 자료를 참조하라.
우리는 실제 사용자 행동을 모방하기 위해 4가지 프롬프트 설정을 테스트에 사용하였다:
(1) 프롬프트 없음: 프롬프트 없이 조건 이미지만 사용.
(2) 불충분한 프롬프트: 조건 이미지의 객체를 충분히 설명하지 않는 프롬프트, 예: 본 논문의 기본 프롬프트인 "a high-quality, detailed, and professional image".
(3) 상충하는 프롬프트: 조건 이미지의 의미론을 변경하는 프롬프트.
(4) 완벽한 프롬프트: 필요한 콘텐츠 의미론을 완전히 설명하는 프롬프트, 예: "a nice house".
Figure 8a는 ControlNet이 이 4가지 설정 모두에서 성공적으로 동작함을 보여준다. 반면, 경량화된 ControlNet-lite(Figure 8c)는 조건 이미지를 해석하는 데 충분히 강력하지 않아 **불충분한 프롬프트**와 **프롬프트 없음** 조건에서 실패하였다. 제로 컨볼루션이 대체된 경우(Figure 8b), ControlNet의 성능은 ControlNet-lite와 유사한 수준으로 하락하였으며, 이는 미세조정 과정에서 학습 가능한 복사본의 사전학습 백본이 손상되었음을 나타낸다.
4.3. Quantitative Evaluation
User study. 우리는 20개의 새로운 손으로 그린 스케치를 샘플링한 후, 각 스케치를 다음 5가지 방법에 할당하였다:
- PITI [89]의 스케치 모델
- Sketch-Guided Diffusion (SGD) (기본 엣지-가이던스 스케일 \(\beta = 1.6\))
- Sketch-Guided Diffusion (SGD) (상대적으로 높은 엣지-가이던스 스케일 \(\beta = 3.2\)),
- ControlNet-lite
- ControlNet.
12명의 사용자에게 각 스케치의 5가지 결과 그룹(총 20개 그룹)을 개별적으로 평가하도록 요청하였다. 평가 기준은 "이미지의 품질"과 "스케치에 대한 충실도"였다. 이 과정에서, 결과 품질에 대한 100개의 순위와 조건 충실도에 대한 100개의 순위를 수집하였다. 선호도를 측정하기 위해 평균 사용자 순위(Average Human Ranking, AHR)를 메트릭으로 사용하였으며, 사용자는 각 결과를 1에서 5까지의 척도로 평가하였다 (점수가 낮을수록 더 나은 결과를 의미). 평균 순위 결과는 Table 1에 나타나 있다.

Comparison to industrial models. Stable Diffusion V2 Depth-to-Image (SDv2-D2I)는 대규모 NVIDIA A100 클러스터에서 수천 시간의 GPU 연산과 1,200만 개 이상의 학습 이미지를 사용하여 학습되었다. 반면, 우리는 동일한 깊이 조건(depth conditioning)을 사용하여 SD V2를 위한 ControlNet을 학습하였으며, 이때 20만 개의 학습 샘플만 사용하고 단일 NVIDIA RTX 3090Ti GPU에서 5일 동안 학습을 진행하였다. 비교를 위해, 각 SDv2-D2I와 ControlNet으로 생성된 100개의 이미지를 사용하여 12명의 사용자에게 두 방법을 구별하는 방법을 학습시켰다. 이후, 200개의 이미지를 생성한 후, 각 이미지가 어떤 모델에서 생성된 것인지 사용자들에게 판별하도록 요청하였다. 사용자들의 평균 정밀도는 \( 0.52 \pm 0.17 \)로, 이는 두 방법의 결과가 거의 구별할 수 없음을 나타낸다.
Condition reconstruction and FID score. 우리는 ADE20K의 테스트 세트를 사용하여 조건 충실도(conditioning fidelity)를 평가하였다. 최신 세그멘테이션 방법인 OneFormer는 ADE20K의 실제 데이터셋(ground truth set)에서 \(0.58\)의 교차합집합비율(Intersection-over-Union, IoU)을 달성하였다. 우리는 ADE20K 세그멘테이션으로 이미지를 생성한 후, OneFormer를 사용하여 다시 세그멘테이션을 검출하고 재구성된 IoU를 계산하였다 (Table 2). 추가적으로, Frechet Inception Distance (FID)]를 사용하여 세그멘테이션 기반 조건부 방법들로 임의 생성된 \(512 \times 512\) 이미지 세트 간의 분포 거리를 측정하였다. 또한, 텍스트-이미지 CLIP 점수 [66]와 CLIP 미적 점수(aesthetic score) [79]를 계산하였다(Table 3).

4.4. Comparison to Previous Methods

Figure 9는 기존 기준선 모델들과 본 방법(Stable Diffusion + ControlNet)의 시각적 비교를 보여준다. 구체적으로, PITI, Sketch-Guided Diffusion, 그리고 Taming Transformers의 결과를 포함하였다. (참고로, PITI의 백본은 OpenAI GLIDE이며, 이는 다른 시각적 품질과 성능을 가진다.) 비교 결과, ControlNet은 다양한 조건 이미지를 견고하게 처리할 수 있으며, 선명하고 깨끗한 결과를 달성함을 관찰하였다.
4.5. Discussion

Influence of training dataset sizes. Figure 10은 ControlNet 학습의 견고성을 보여준다. 제한된 1,000개의 이미지로 학습해도 학습이 붕괴되지 않으며, 모델이 인식 가능한 사자를 생성할 수 있다. 또한, 더 많은 데이터가 제공될수록 학습은 확장 가능하다.

Capability to interpret contents. Figure 11은 입력 조건 이미지를 통해 ControlNet이 의미(semantics)를 포착하는 능력을 보여준다. 이 결과는 ControlNet이 조건 이미지의 내용을 효과적으로 해석할 수 있음을 입증한다.

Transferring to community models. ControlNet은 사전학습된 Stable Diffusion 모델의 네트워크 구조를 변경하지 않기 때문에, Stable Diffusion 커뮤니티의 다양한 모델(예: Comic Diffusion, Protogen 3.4)에 직접 적용할 수 있다. Figure 12는 이러한 전이 가능성을 시각적으로 보여준다.
5. Conclusion
ControlNet은 대규모 사전학습된 텍스트-이미지 diffusion 모델을 위한 조건부 제어를 학습하는 신경망 구조이다. 이는 소스 모델의 대규모 사전학습 레이어를 재사용하여 특정 조건을 학습하기 위한 깊고 강력한 인코더를 구축한다. 원본 모델과 학습 가능한 복사본은 학습 중 유해한 노이즈를 제거하는 "제로 컨볼루션" 레이어로 연결된다.
광범위한 실험을 통해 ControlNet이 단일 또는 다중 조건에서, 프롬프트의 유무에 관계없이 Stable Diffusion을 효과적으로 제어할 수 있음을 검증하였다. 다양한 조건 데이터셋에 대한 결과는 ControlNet 구조가 더 넓은 범위의 조건에 적용 가능하며, 관련 응용을 촉진할 가능성이 높음을 보여준다.



